Publications
Publications in PolySmart Group.
2026
- AAAI
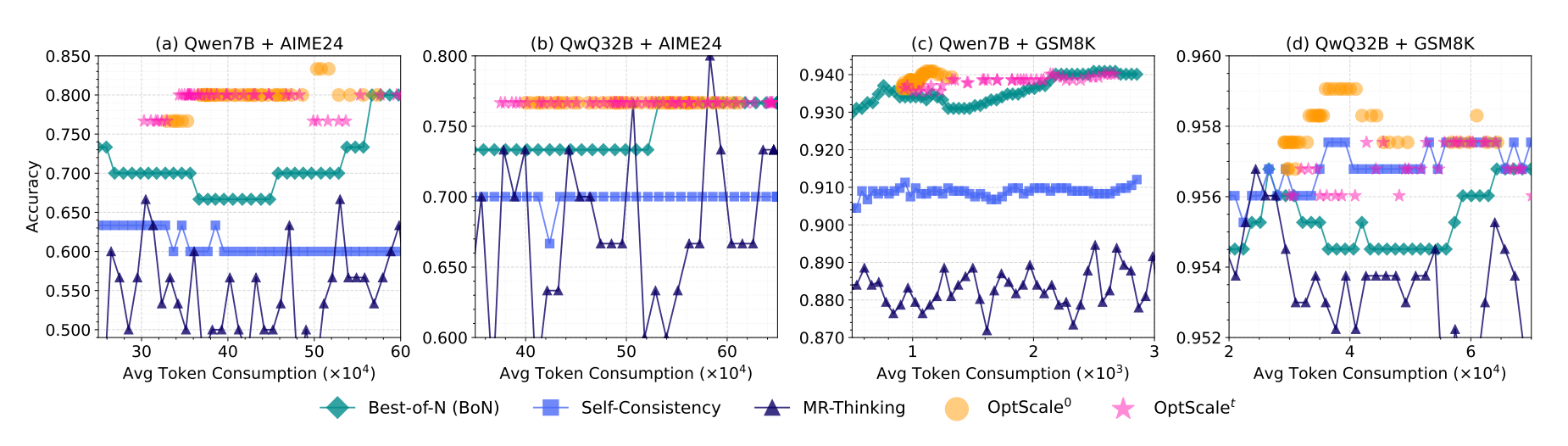 OptScale: Probabilistic Optimality for Inference-time ScalingYoukang Wang, Jian Wang, Rubing Chen, and Xiao-Yong WeiProceedings of the AAAI Conference on Artificial Intelligence, Mar 2026
OptScale: Probabilistic Optimality for Inference-time ScalingYoukang Wang, Jian Wang, Rubing Chen, and Xiao-Yong WeiProceedings of the AAAI Conference on Artificial Intelligence, Mar 2026@article{Wang_Wang_Chen_Wei_2026, title = {OptScale: Probabilistic Optimality for Inference-time Scaling}, volume = {40}, url = {https://ojs.aaai.org/index.php/AAAI/article/view/40661}, doi = {10.1609/aaai.v40i40.40661}, abstractnote = {Inference-time scaling has emerged as a powerful technique for enhancing the reasoning performance of Large Language Models (LLMs). However, existing approaches often rely on heuristic strategies for parallel sampling, lacking a principled foundation. To address this gap, we propose a probabilistic framework that formalizes the optimality of inference-time scaling under the assumption that parallel samples are independently and identically distributed (i.i.d.), and where the Best-of-N selection strategy follows a probability distribution that can be estimated. Within this framework, we derive a theoretical lower bound on the required number of samples to achieve a target performance level, providing the first principled guidance for compute-efficient scaling. Leveraging this insight, we develop OptScale, a practical algorithm that dynamically determines the optimal number of sampled responses. OptScale employs a language model-based predictor to estimate probabilistic prior parameters, enabling the decision of the minimal number of samples needed that satisfy predefined performance thresholds and confidence levels. Extensive experiments on representative reasoning benchmarks (including MATH-500, GSM8K, AIME, and AMC) demonstrate that OptScale significantly reduces sampling overhead while remaining better or on par with state-of-the-art reasoning performance. Our work offers both a theoretical foundation and a practical solution for principled inference-time scaling, addressing a critical gap in the efficient deployment of LLMs for complex reasoning.}, number = {40}, journal = {Proceedings of the AAAI Conference on Artificial Intelligence}, author = {Wang, Youkang and Wang, Jian and Chen, Rubing and Wei, Xiao-Yong}, year = {2026}, month = mar, pages = {33710-33718} }

2025
- CVPR
 Sound Bridge: Associating Egocentric and Exocentric Videos via Audio CuesSihong Huang, Jiaxin Wu, Xiaoyong Wei, Yi Cai, Dongmei Jiang, and Yaowei WangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025
Sound Bridge: Associating Egocentric and Exocentric Videos via Audio CuesSihong Huang, Jiaxin Wu, Xiaoyong Wei, Yi Cai, Dongmei Jiang, and Yaowei WangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025@inproceedings{Huang_2025_CVPR, author = {Huang, Sihong and Wu, Jiaxin and Wei, Xiaoyong and Cai, Yi and Jiang, Dongmei and Wang, Yaowei}, title = {Sound Bridge: Associating Egocentric and Exocentric Videos via Audio Cues}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, year = {2025}, pages = {28942-28951}, } - IEEE Transactions on Medical Imaging
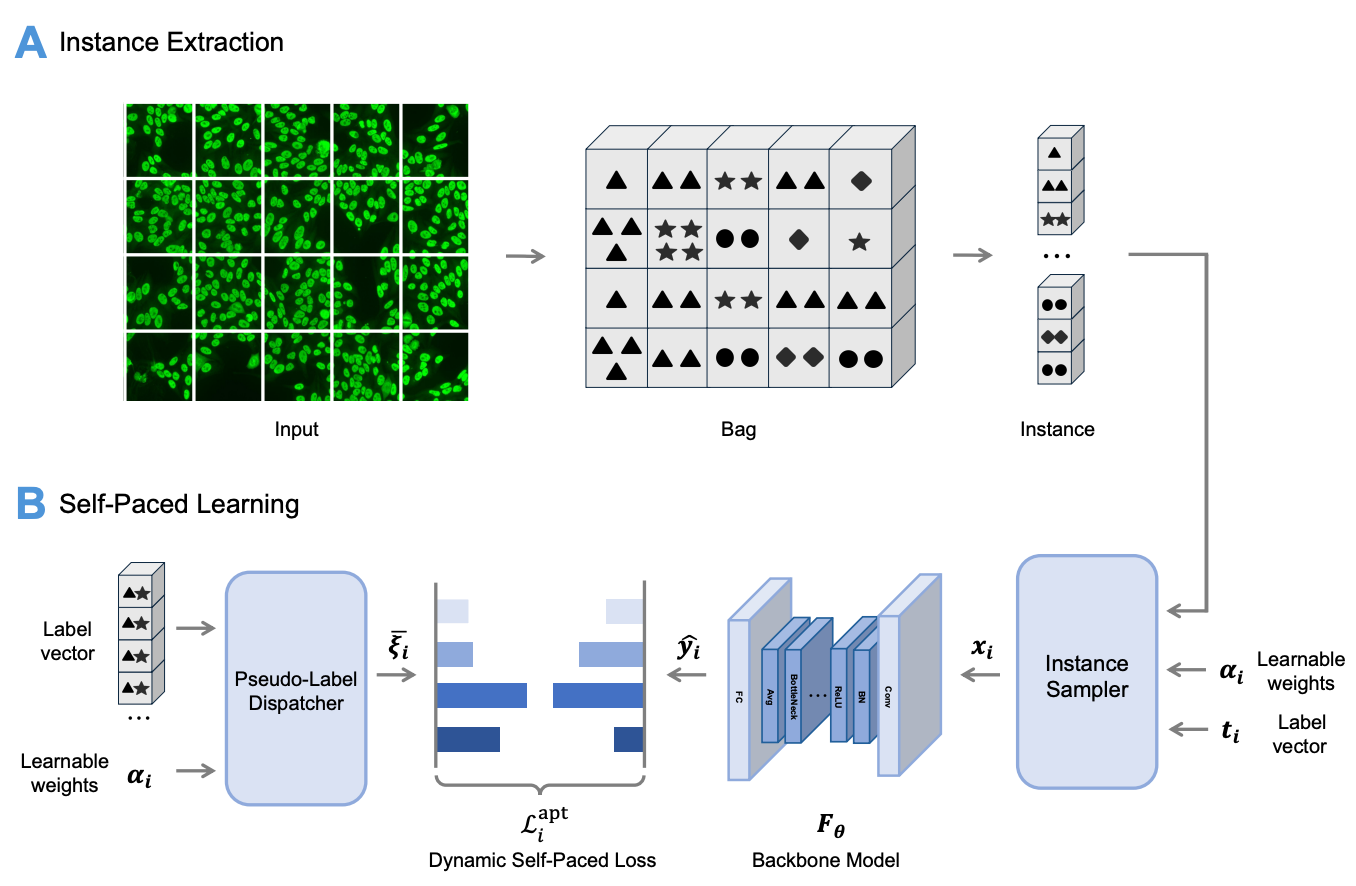 Self-paced learning for images of antinuclear antibodiesYiyang Jiang, Guangwu Qian, Jiaxin Wu, Qi Huang, Qing Li, Yongkang Wu, and Xiao-Yong WeiIEEE Transactions on Medical Imaging, Jun 2025
Self-paced learning for images of antinuclear antibodiesYiyang Jiang, Guangwu Qian, Jiaxin Wu, Qi Huang, Qing Li, Yongkang Wu, and Xiao-Yong WeiIEEE Transactions on Medical Imaging, Jun 2025@article{jiang2025self, title = {Self-paced learning for images of antinuclear antibodies}, author = {Jiang, Yiyang and Qian, Guangwu and Wu, Jiaxin and Huang, Qi and Li, Qing and Wu, Yongkang and Wei, Xiao-Yong}, journal = {IEEE Transactions on Medical Imaging}, year = {2025}, publisher = {IEEE}, } - Machine Intelligence Research
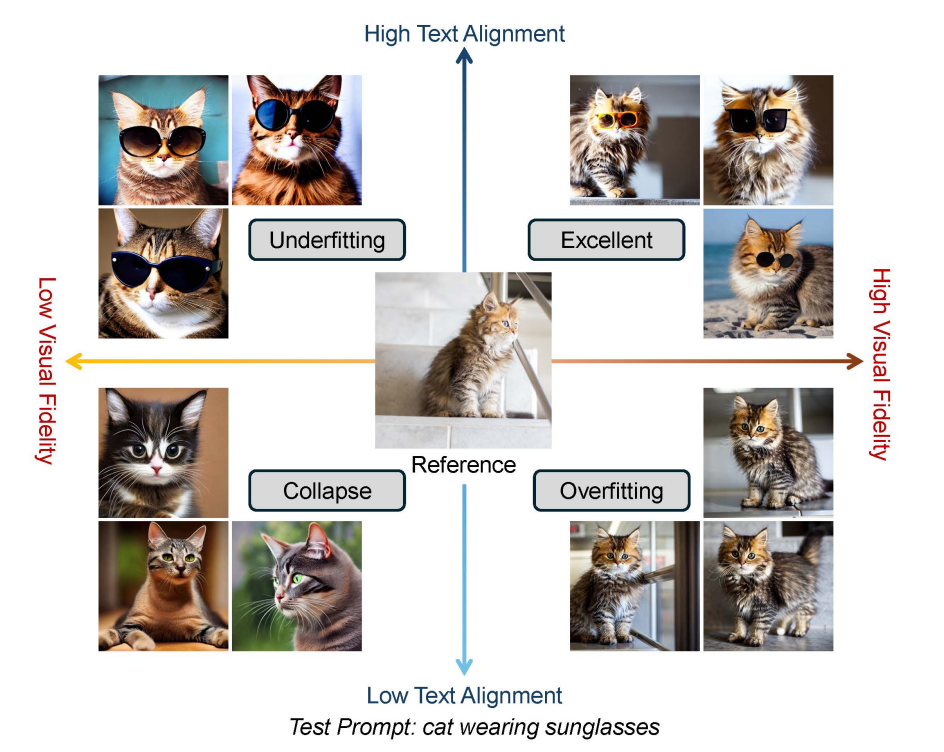 A survey on personalized content synthesis with diffusion modelsXulu Zhang, Xiaoyong Wei, Wentao Hu, Jinlin Wu, Jiaxin Wu, Wengyu Zhang, Zhaoxiang Zhang, Zhen Lei, and Qing LiMachine Intelligence Research, Jun 2025
A survey on personalized content synthesis with diffusion modelsXulu Zhang, Xiaoyong Wei, Wentao Hu, Jinlin Wu, Jiaxin Wu, Wengyu Zhang, Zhaoxiang Zhang, Zhen Lei, and Qing LiMachine Intelligence Research, Jun 2025@article{zhang2025survey, title = {A survey on personalized content synthesis with diffusion models}, author = {Zhang, Xulu and Wei, Xiaoyong and Hu, Wentao and Wu, Jinlin and Wu, Jiaxin and Zhang, Wengyu and Zhang, Zhaoxiang and Lei, Zhen and Li, Qing}, journal = {Machine Intelligence Research}, volume = {22}, number = {5}, pages = {817--848}, doi = {10.1007/s11633-025-1563-3}, year = {2025}, publisher = {Springer} } - npj Materials Sustainability
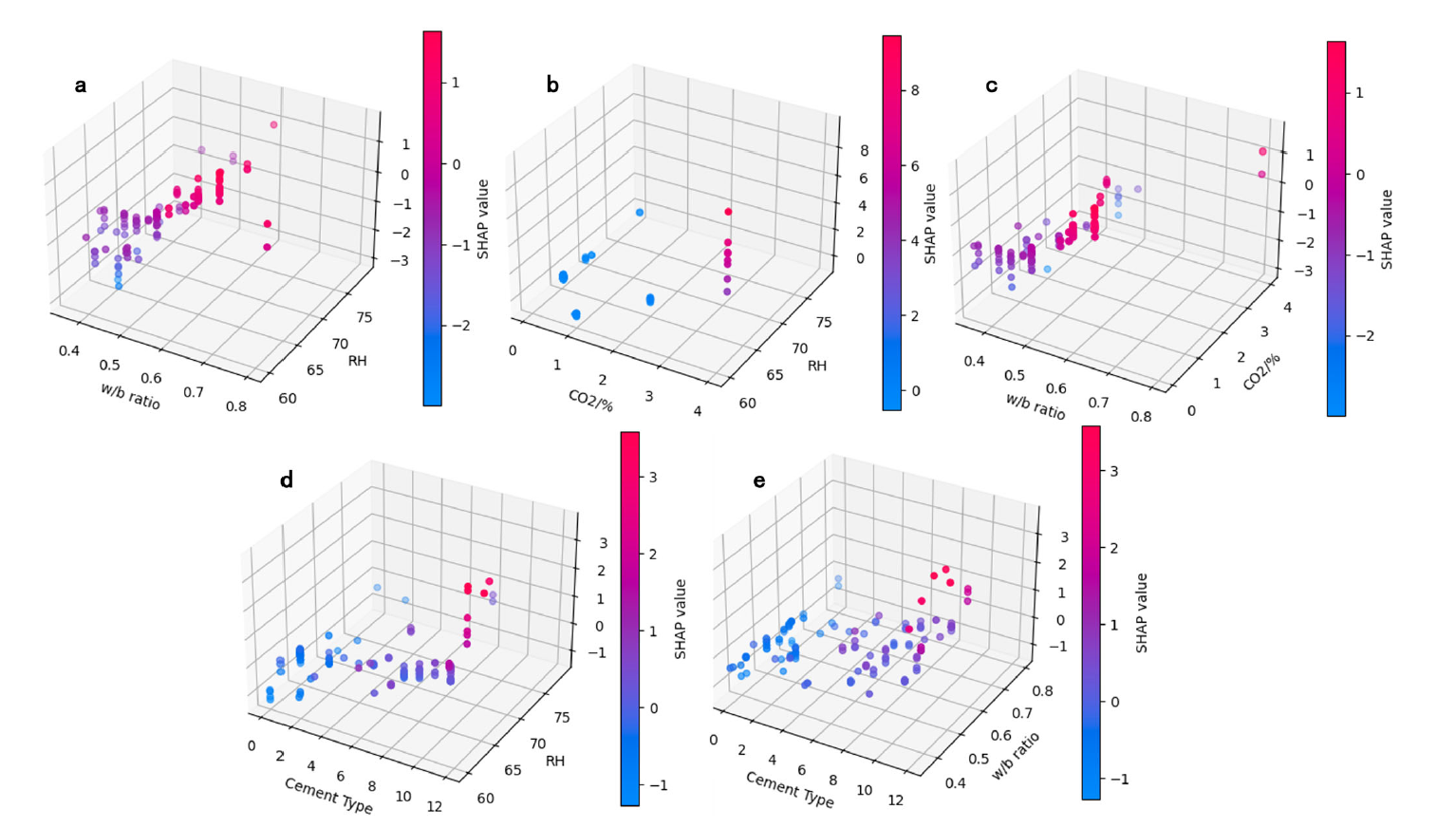 Machine learning for efficient CO2 sequestration in cementitious materials: a data-driven methodYanjie Sun, Chen Zhang, Yuan-Hao Wei, Haoliang Jin, Peiliang Shen, Chi Sun Poon, He Yan, and Xiao-Yong Weinpj Materials Sustainability, Jun 2025
Machine learning for efficient CO2 sequestration in cementitious materials: a data-driven methodYanjie Sun, Chen Zhang, Yuan-Hao Wei, Haoliang Jin, Peiliang Shen, Chi Sun Poon, He Yan, and Xiao-Yong Weinpj Materials Sustainability, Jun 2025@article{sun2025machine, title = {Machine learning for efficient CO2 sequestration in cementitious materials: a data-driven method}, author = {Sun, Yanjie and Zhang, Chen and Wei, Yuan-Hao and Jin, Haoliang and Shen, Peiliang and Poon, Chi Sun and Yan, He and Wei, Xiao-Yong}, journal = {npj Materials Sustainability}, volume = {3}, number = {1}, pages = {9}, year = {2025}, publisher = {Nature Publishing Group UK London}, } - EMNLP Findings
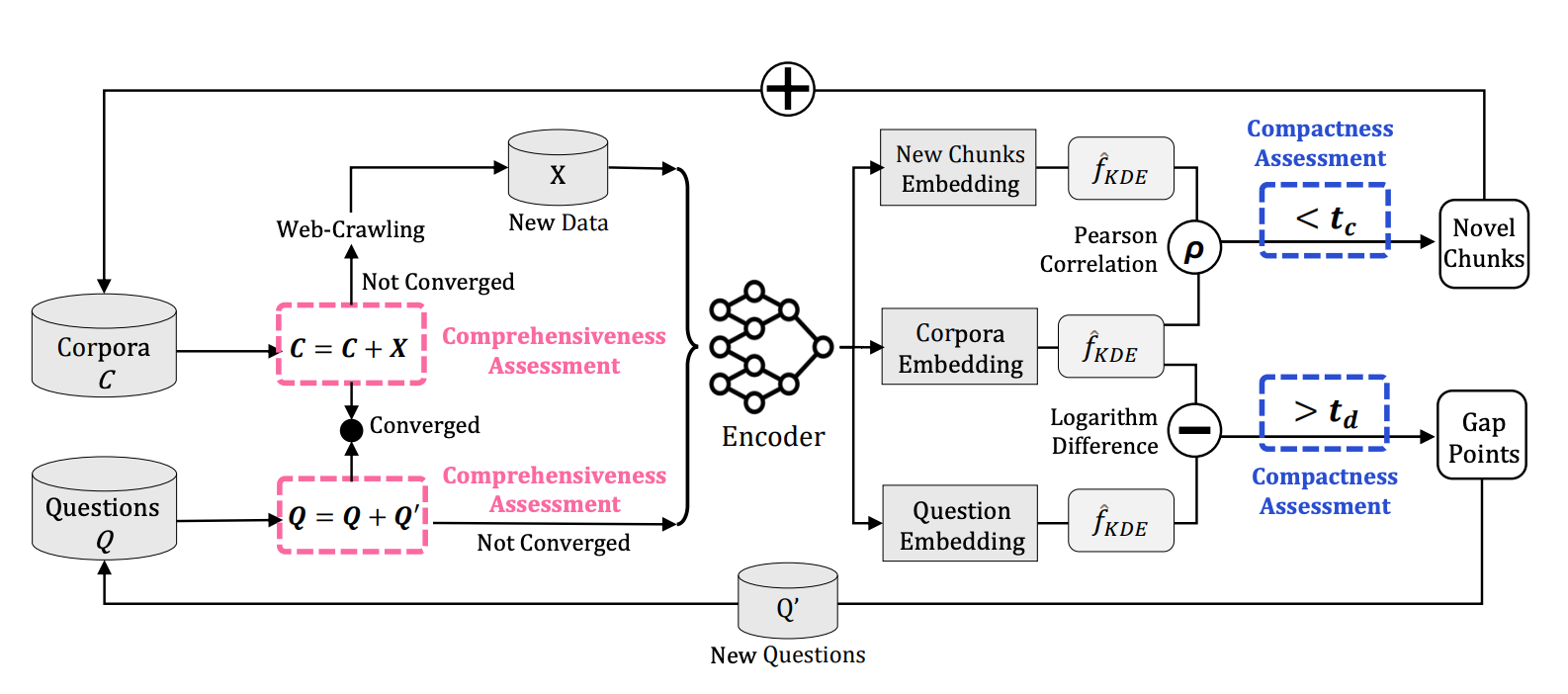 Benchmarking for Domain-Specific LLMs: A Case Study on Academia and BeyondRubing Chen, Jiaxin Wu, Jian Wang, Xulu Zhang, Wenqi Fan, Chenghua Lin, Xiaoyong Wei, and Qing LiIn Findings of the Association for Computational Linguistics: EMNLP 2025 , Nov 2025
Benchmarking for Domain-Specific LLMs: A Case Study on Academia and BeyondRubing Chen, Jiaxin Wu, Jian Wang, Xulu Zhang, Wenqi Fan, Chenghua Lin, Xiaoyong Wei, and Qing LiIn Findings of the Association for Computational Linguistics: EMNLP 2025 , Nov 2025The increasing demand for domain-specific evaluation of large language models (LLMs) has led to the development of numerous benchmarks. These efforts often adhere to the principle of data scaling, relying on large corpora or extensive question-answer (QA) sets to ensure broad coverage. However, the impact of corpus and QA set design on the precision and recall of domain-specific LLM performance remains poorly understood. In this paper, we argue that data scaling is not always the optimal principle for domain-specific benchmark construction. Instead, we introduce Comp-Comp, an iterative benchmarking framework grounded in the principle of comprehensiveness and compactness. Comprehensiveness ensures semantic recall by covering the full breadth of the domain, while compactness improves precision by reducing redundancy and noise. To demonstrate the effectiveness of our approach, we present a case study conducted at a well-renowned university, resulting in the creation of PolyBench, a large-scale, high-quality academic benchmark. Although this study focuses on academia, the Comp-Comp framework is domain-agnostic and readily adaptable to a wide range of specialized fields. The source code and datasets can be accessed at https://github.com/Anya-RB-Chen/COMP-COMP.
@inproceedings{chen-etal-2025-benchmarking-domain, title = {Benchmarking for Domain-Specific {LLM}s: A Case Study on Academia and Beyond}, author = {Chen, Rubing and Wu, Jiaxin and Wang, Jian and Zhang, Xulu and Fan, Wenqi and Lin, Chenghua and Wei, Xiaoyong and Li, Qing}, editor = {Christodoulopoulos, Christos and Chakraborty, Tanmoy and Rose, Carolyn and Peng, Violet}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2025}, month = nov, year = {2025}, address = {Suzhou, China}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.findings-emnlp.622/}, doi = {10.18653/v1/2025.findings-emnlp.622}, pages = {11606--11619}, isbn = {979-8-89176-335-7}, } - EMNLP Findings
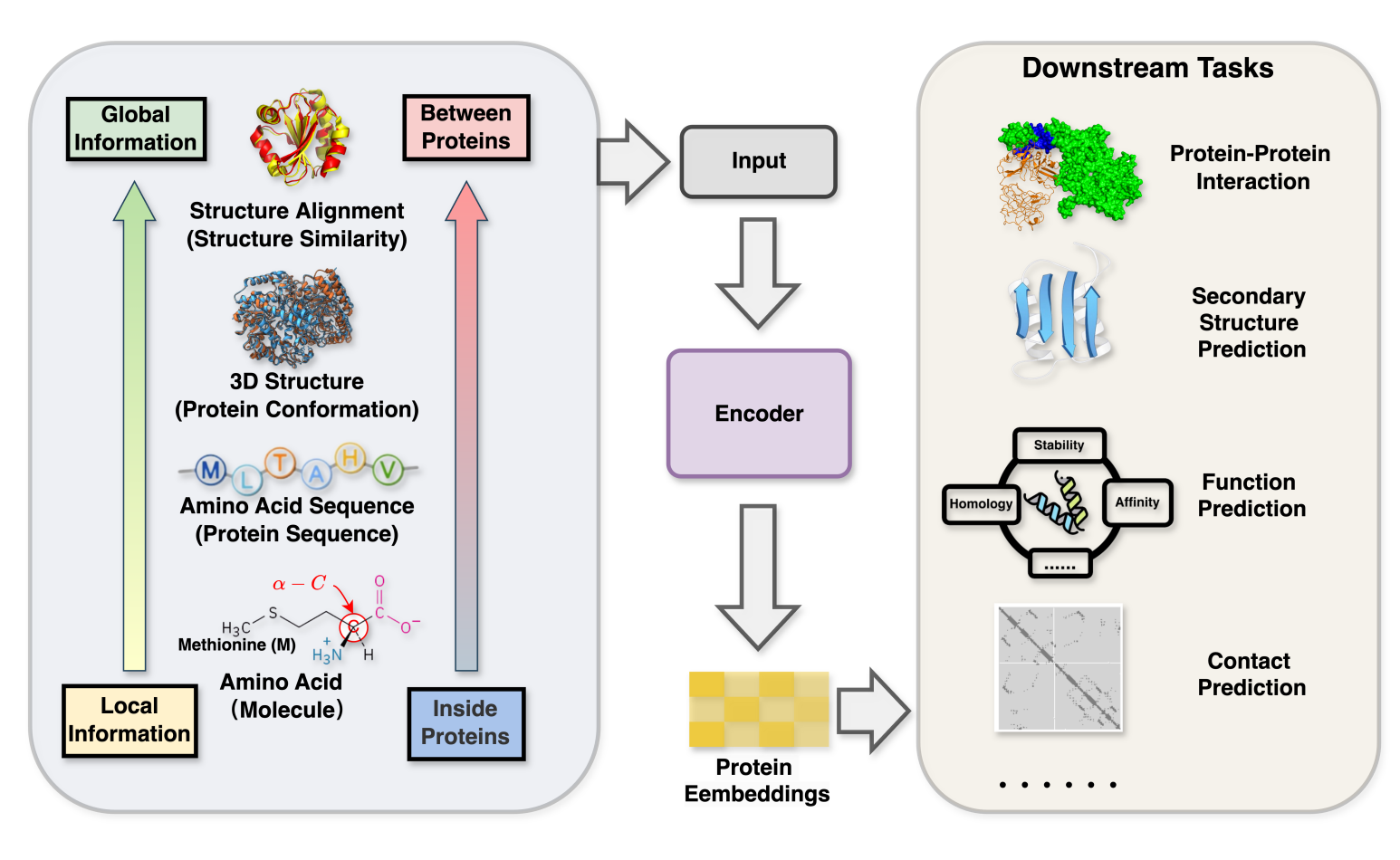 GLProtein: Global-and-Local Structure Aware Protein Representation LearningYunqing Liu, Wenqi Fan, Xiaoyong Wei, and Qing LiIn Findings of the Association for Computational Linguistics: EMNLP 2025 , Nov 2025
GLProtein: Global-and-Local Structure Aware Protein Representation LearningYunqing Liu, Wenqi Fan, Xiaoyong Wei, and Qing LiIn Findings of the Association for Computational Linguistics: EMNLP 2025 , Nov 2025analysis, there remains potential for further exploration in integrating protein structural information. We argue that the structural information of proteins is not only limited to their 3D information but also encompasses information from amino acid molecules (local information) to protein-protein structure similarity (global information). To address this, we propose \textbfGLProtein, the first framework in protein pre-training that incorporates both global structural similarity and local amino acid details to enhance prediction accuracy and functional insights. GLProtein innovatively combines protein-masked modelling with triplet structure similarity scoring, protein 3D distance encoding and substructure-based amino acid molecule encoding. Experimental results demonstrate that GLProtein outperforms previous methods in several bioinformatics tasks, including predicting protein-protein interaction, contact prediction, and so on.
@inproceedings{liu2025glprotein, title = {GLProtein: Global-and-Local Structure Aware Protein Representation Learning}, author = {Liu, Yunqing and Fan, Wenqi and Wei, Xiaoyong and Li, Qing}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2025}, pages = {4355--4372}, year = {2025}, } - IEEE Transactions on Mobile Computing
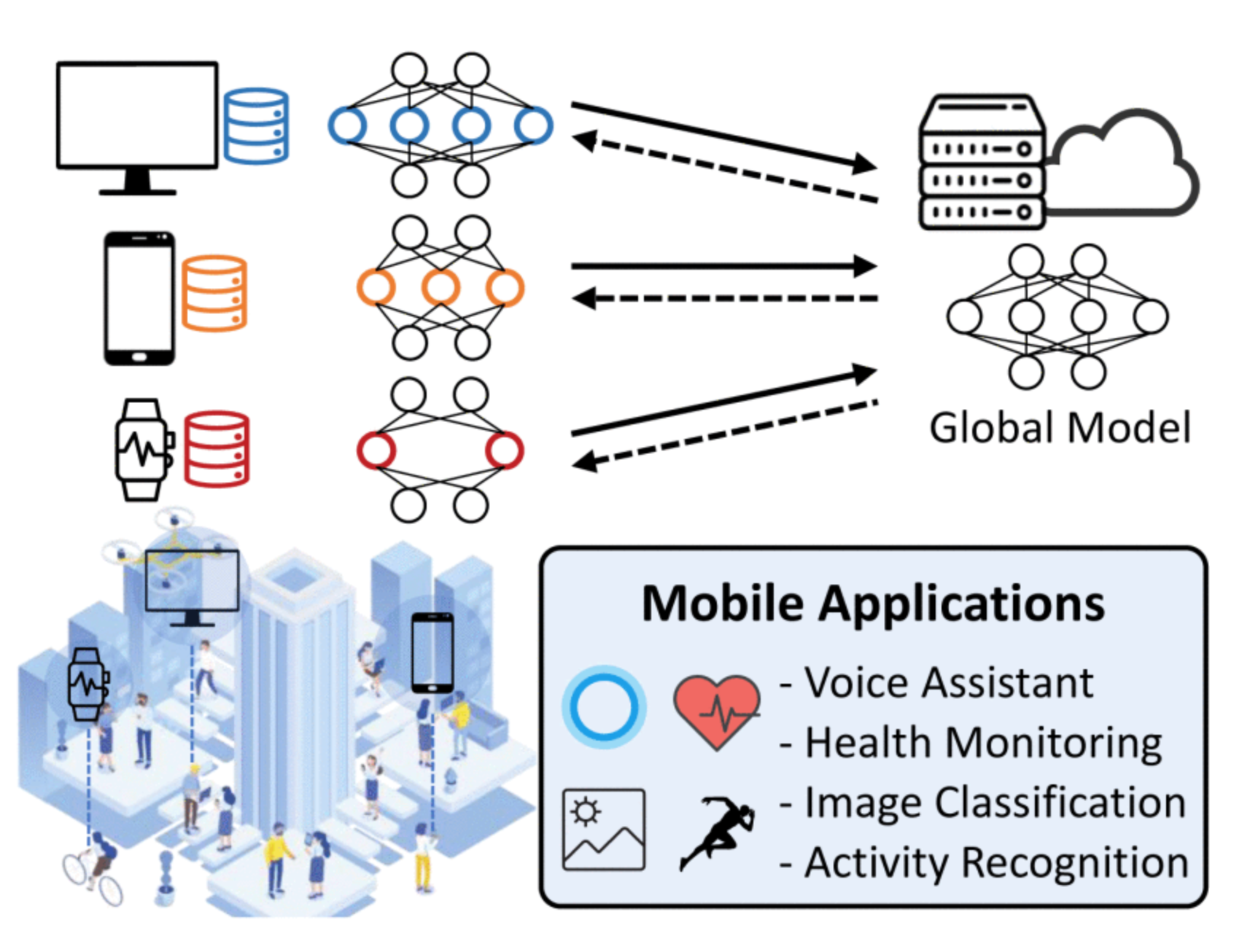 Hierarchical and heterogeneous federated learning via a learning-on-model paradigmLeming Shen, Qiang Yang, Kaiyan Cui, Yuanqing Zheng, Xiao-Yong Wei, Jianwei Liu, and Jinsong HanIEEE Transactions on Mobile Computing, Nov 2025
Hierarchical and heterogeneous federated learning via a learning-on-model paradigmLeming Shen, Qiang Yang, Kaiyan Cui, Yuanqing Zheng, Xiao-Yong Wei, Jianwei Liu, and Jinsong HanIEEE Transactions on Mobile Computing, Nov 2025Federated Learning (FL) collaboratively trains a shared global model without exposing clients’ private data. In practical FL systems, clients (e.g., smartphones and wearables) typically have disparate system resources. Traditional FL, however, adopts a one-size-fits-all solution, where a homogeneous large model is sent to and trained on each client. This method results in an overwhelming workload for less capable clients and starvation for others. To tackle this, we propose FedConv, a client-friendly FL framework, minimizing the system overhead on resource-constrained clients by providing heterogeneous customized sub-models. FedConv features a novel learning-on-model paradigm that learns the parameters of heterogeneous sub-models via convolutional compression. To aggregate heterogeneous sub-models, we propose transposed convolutional dilation to convert them back to large models with a unified size while retaining personalized information. The compression and dilation processes, transparent to clients, are tuned on the server using a small public dataset. We further propose a hierarchical and clustering-based local training strategy for enhanced performance. Extensive experiments on six datasets show that FedConv outperforms state-of-the-art FL systems in terms of model accuracy (by more than 35% on average), computation and communication overhead (with 33% and 25% reduction, respectively).
@article{shen2025hierarchical, title = {Hierarchical and heterogeneous federated learning via a learning-on-model paradigm}, author = {Shen, Leming and Yang, Qiang and Cui, Kaiyan and Zheng, Yuanqing and Wei, Xiao-Yong and Liu, Jianwei and Han, Jinsong}, journal = {IEEE Transactions on Mobile Computing}, year = {2025}, publisher = {IEEE}, } - ACL
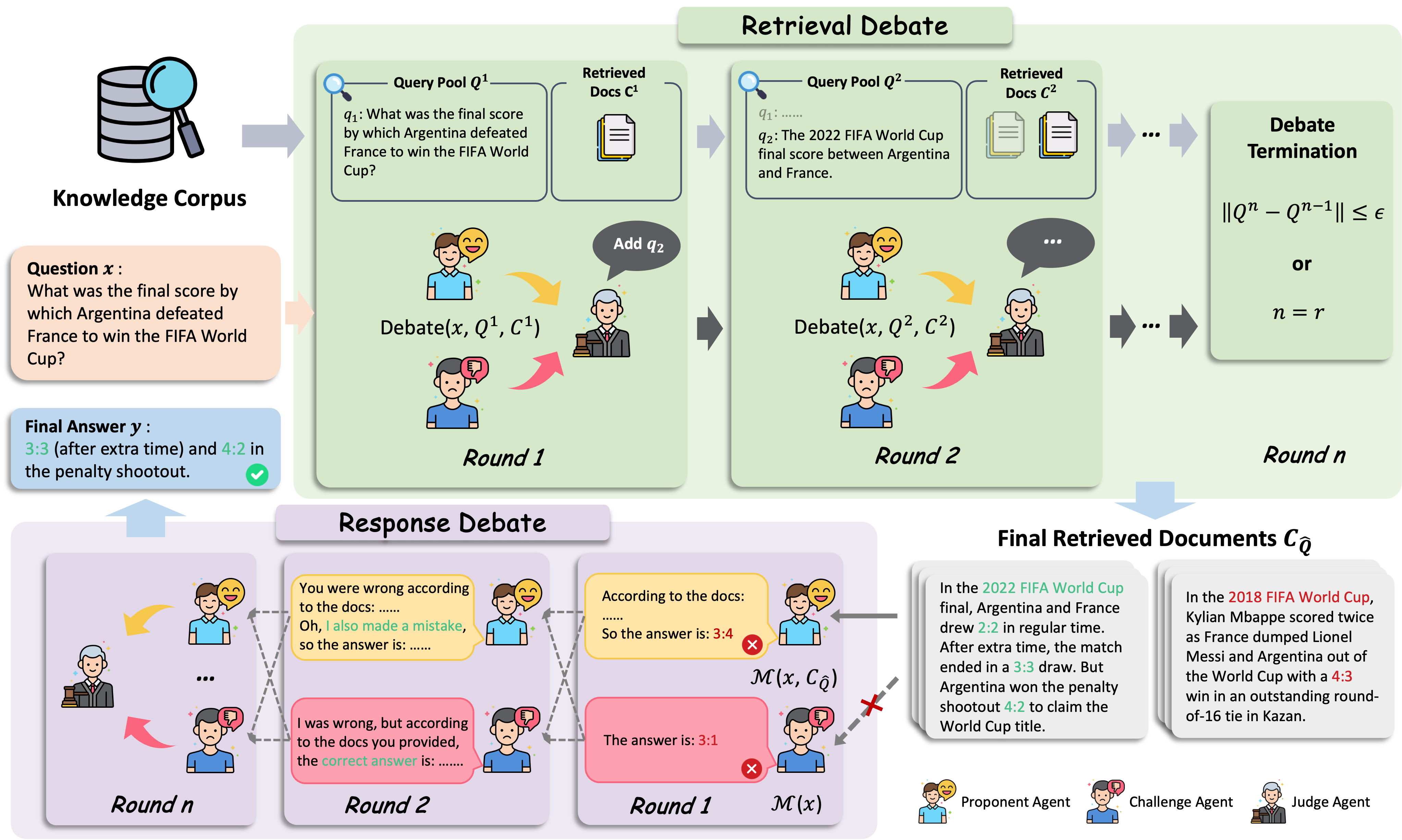 Removal of Hallucination on Hallucination: Debate-Augmented RAGWentao Hu, Wengyu Zhang, Yiyang Jiang, Chen Jason Zhang, Xiaoyong Wei, and Qing LiIn ACL 2025 Main , Nov 2025
Removal of Hallucination on Hallucination: Debate-Augmented RAGWentao Hu, Wengyu Zhang, Yiyang Jiang, Chen Jason Zhang, Xiaoyong Wei, and Qing LiIn ACL 2025 Main , Nov 2025Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external knowledge, yet it introduces a critical issue: erroneous or biased retrieval can mislead generation, compounding hallucinations, a phenomenon we term Hallucination on Hallucination. To address this, we propose Debate Augmented RAG (DRAG), a training-free framework that integrates Multi-Agent Debate (MAD) mechanisms into both retrieval and generation stages. In retrieval, DRAG employs structured debates among proponents, opponents, and judges to refine retrieval quality and ensure factual reliability. In generation, DRAG introduces asymmetric information roles and adversarial debates, enhancing reasoning robustness and mitigating factual inconsistencies. Evaluations across multiple tasks demonstrate that DRAG improves retrieval reliability, reduces RAG-induced hallucinations, and significantly enhances overall factual accuracy. Our code is available at https://github.com/Huenao/Debate-Augmented-RAG.
@inproceedings{hu2025removal, title = {Removal of Hallucination on Hallucination: Debate-Augmented RAG}, author = {Hu, Wentao and Zhang, Wengyu and Jiang, Yiyang and Zhang, Chen Jason and Wei, Xiaoyong and Li, Qing}, booktitle = {ACL 2025 Main}, year = {2025}, } - Briefings in Bioinformatics
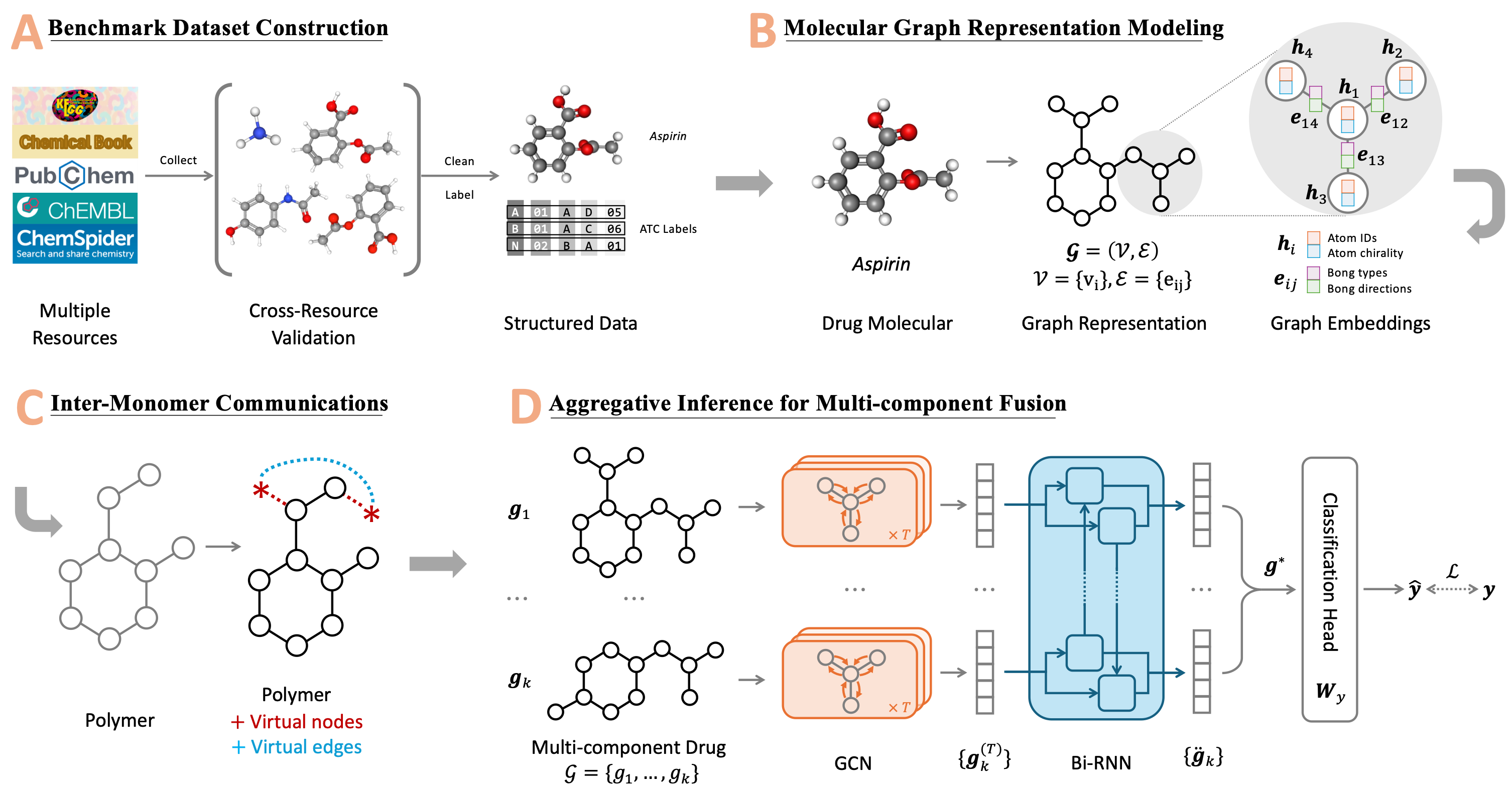 GraphATC: advancing multilevel and multi-label anatomical therapeutic chemical classification via atom-level graph learningWengyu Zhang, Qi Tian, Yi Cao, Wenqi Fan, Dongmei Jiang, Yaowei Wang, Qing Li, and Xiao-Yong WeiBriefings in Bioinformatics, Apr 2025
GraphATC: advancing multilevel and multi-label anatomical therapeutic chemical classification via atom-level graph learningWengyu Zhang, Qi Tian, Yi Cao, Wenqi Fan, Dongmei Jiang, Yaowei Wang, Qing Li, and Xiao-Yong WeiBriefings in Bioinformatics, Apr 2025The accurate categorization of compounds within the anatomical therapeutic chemical (ATC) system is fundamental for drug development and fundamental research. Although this area has garnered significant research focus for over a decade, the majority of prior studies have concentrated solely on the Level 1 labels defined by the World Health Organization (WHO), neglecting the labels of the remaining four levels. This narrow focus fails to address the true nature of the task as a multilevel, multi-label classification challenge. Moreover, existing benchmarks like Chen-2012 and ATC-SMILES have become outdated, lacking the incorporation of new drugs or updated properties of existing ones that have emerged in recent years and have been integrated into the WHO ATC system. To tackle these shortcomings, we present a comprehensive approach in this paper. Firstly, we systematically cleanse and enhance the drug dataset, expanding it to encompass all five levels through a rigorous cross-resource validation process involving KEGG, PubChem, ChEMBL, ChemSpider, and ChemicalBook. This effort culminates in the creation of a novel benchmark termed ATC-GRAPH. Secondly, we extend the classification task to encompass Level 2 and introduce graph-based learning techniques to provide more accurate representations of drug molecular structures. This approach not only facilitates the modeling of Polymers, Macromolecules, and Multi-Component drugs more precisely but also enhances the overall fidelity of the classification process. The efficacy of our proposed framework is validated through extensive experiments, establishing a new state-of-the-art methodology. To facilitate the replication of this study, we have made the benchmark dataset, source code, and web server openly accessible.
@article{zhang2025graphatc, author = {Zhang, Wengyu and Tian, Qi and Cao, Yi and Fan, Wenqi and Jiang, Dongmei and Wang, Yaowei and Li, Qing and Wei, Xiao-Yong}, title = {GraphATC: advancing multilevel and multi-label anatomical therapeutic chemical classification via atom-level graph learning}, journal = {Briefings in Bioinformatics}, volume = {26}, number = {2}, pages = {bbaf194}, year = {2025}, month = apr, issn = {1477-4054}, doi = {10.1093/bib/bbaf194}, eprint = {https://academic.oup.com/bib/article-pdf/26/2/bbaf194/63012495/bbaf194.pdf}, }









2024
- NIST TRECVID
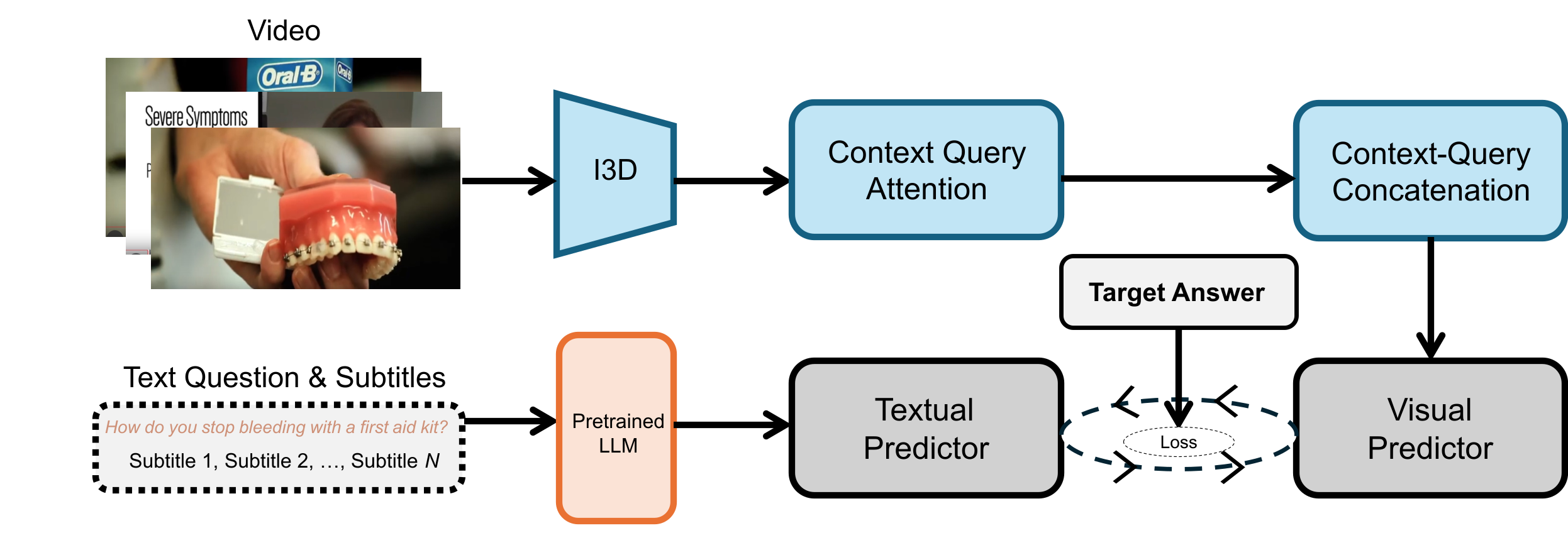 PolySmart @ TRECVid 2024 Medical Video Question AnsweringJiaxin Wu, Yiyang Jiang, Xiao-Yong Wei, and Qing LiIn NIST TRECVID Notebook 2024 , Apr 2024
PolySmart @ TRECVid 2024 Medical Video Question AnsweringJiaxin Wu, Yiyang Jiang, Xiao-Yong Wei, and Qing LiIn NIST TRECVID Notebook 2024 , Apr 2024Video Corpus Visual Answer Localization (VCVAL) includes question-related video retrieval and visual answer localization in the videos. Specifically, we use text-to-text retrieval to find relevant videos for a medical question based on the similarity of video transcript and answers generated by GPT4. For the visual answer localization, the start and end timestamps of the answer are predicted by the alignments on both visual content and subtitles with queries. For the Query-Focused Instructional Step Captioning (QFISC) task, the step captions are generated by GPT4. Specifically, we provide the video captions generated by the LLaVA-Next-Video model and the video subtitles with timestamps as context, and ask GPT4 to generate step captions for the given medical query. We only submit one run for evaluation and it obtains a F-score of 11.92 and mean IoU of 9.6527.
@inproceedings{wu2024polysmarttrecvid2024, title = {PolySmart @ TRECVid 2024 Medical Video Question Answering}, author = {Wu, Jiaxin and Jiang, Yiyang and Wei, Xiao-Yong and Li, Qing}, booktitle = {NIST TRECVID Notebook 2024}, year = {2024}, } - NIST TRECVID
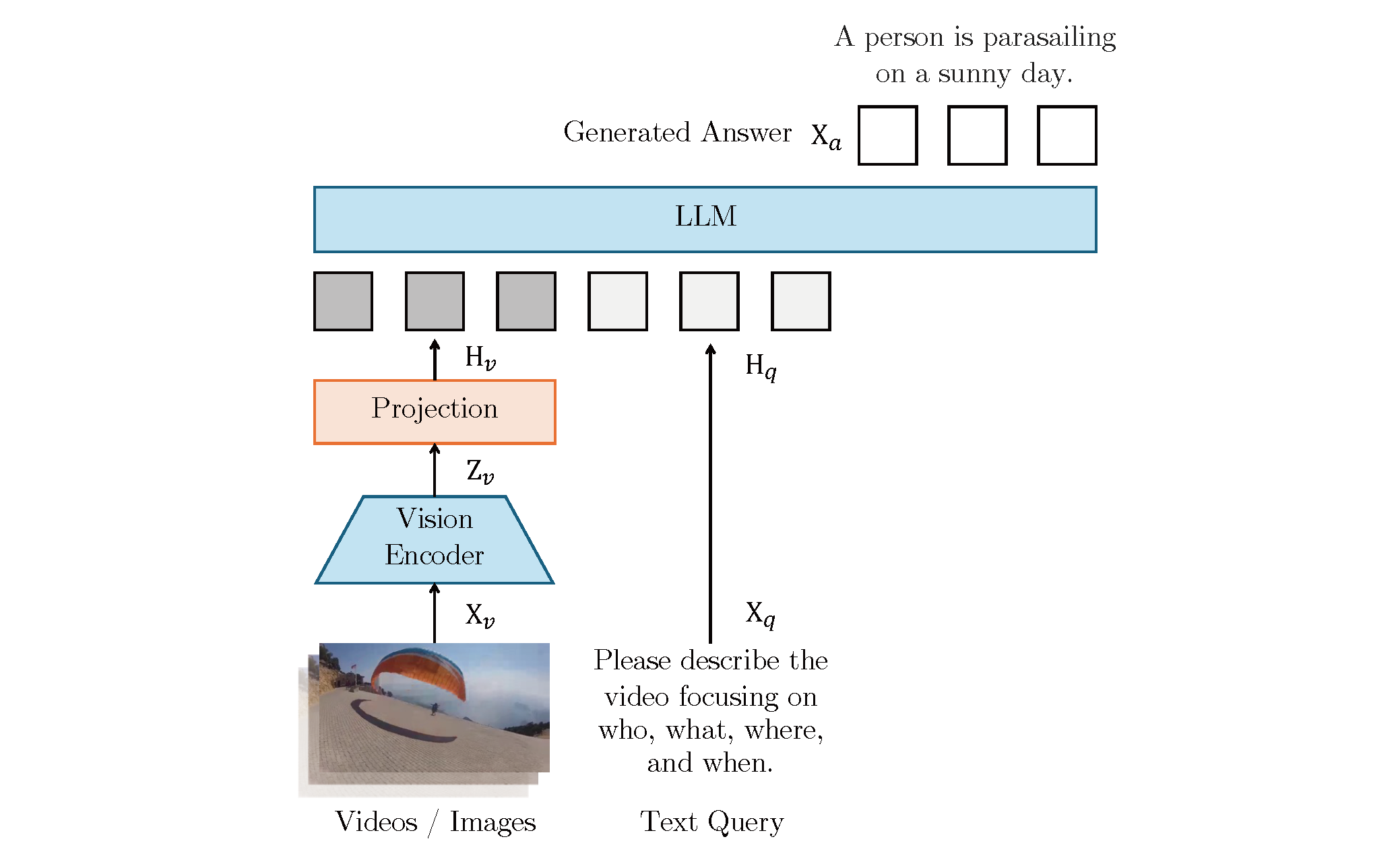 PolySmart @ TRECVid 2024 Video-To-TextJiaxin Wu, Wengyu Zhang, Xiao-Yong Wei, and Qing LiIn NIST TRECVID Notebook 2024 , Apr 2024
PolySmart @ TRECVid 2024 Video-To-TextJiaxin Wu, Wengyu Zhang, Xiao-Yong Wei, and Qing LiIn NIST TRECVID Notebook 2024 , Apr 2024In this paper, we present our methods and results for the Video-To-Text (VTT) task at TRECVid 2024, exploring the capabilities of Vision-Language Models (VLMs) like LLaVA and LLaVA-NeXT-Video in generating natural language descriptions for video content. We investigate the impact of fine-tuning VLMs on VTT datasets to enhance description accuracy, contextual relevance, and linguistic consistency. Our analysis reveals that fine-tuning substantially improves the model’s ability to produce more detailed and domain-aligned text, bridging the gap between generic VLM tasks and the specialized needs of VTT. Experimental results demonstrate that our fine-tuned model outperforms baseline VLMs across various evaluation metrics, underscoring the importance of domain-specific tuning for complex VTT tasks.
@inproceedings{wu2024polysmarttrecvid2025, title = {PolySmart @ TRECVid 2024 Video-To-Text}, author = {Wu, Jiaxin and Zhang, Wengyu and Wei, Xiao-Yong and Li, Qing}, booktitle = {NIST TRECVID Notebook 2024}, year = {2024}, } - NIST TRECVID
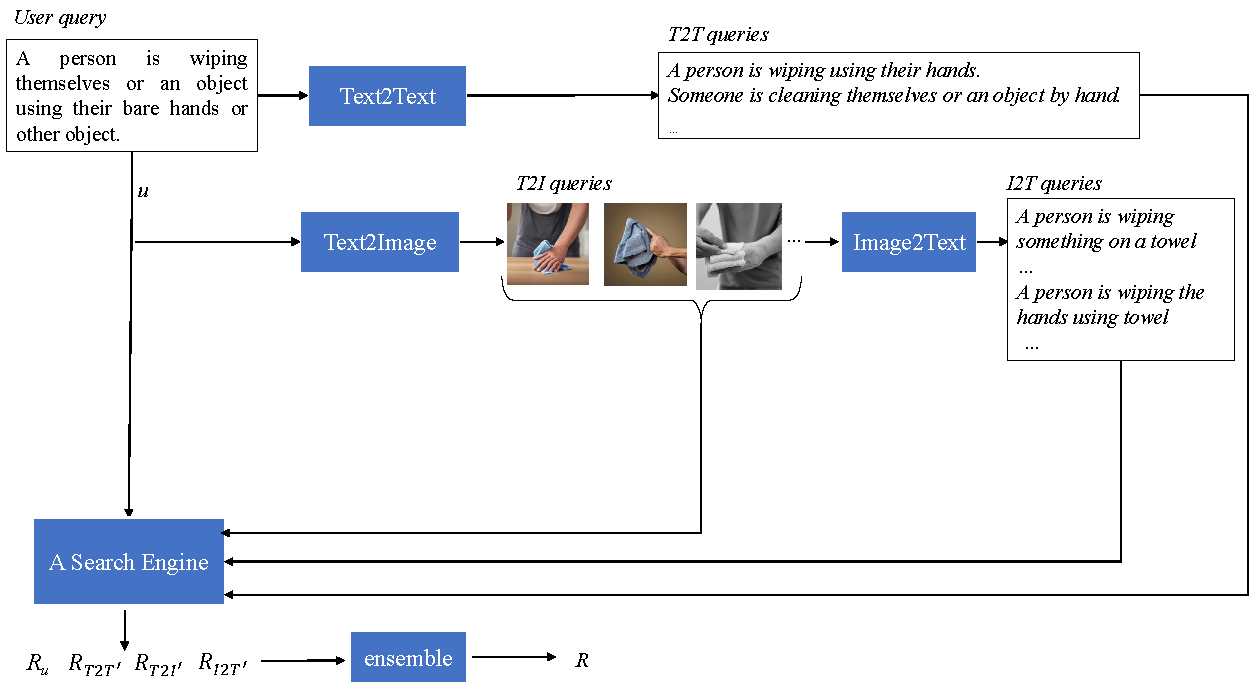 PolySmart and VIREO @ TRECVid 2024 Ad-hoc Video SearchJiaxin Wu, Chong-Wah Ngo, Xiao-Yong Wei, and Qing LiIn NIST TRECVID Notebook 2024 , Apr 2024
PolySmart and VIREO @ TRECVid 2024 Ad-hoc Video SearchJiaxin Wu, Chong-Wah Ngo, Xiao-Yong Wei, and Qing LiIn NIST TRECVID Notebook 2024 , Apr 2024This year, we explore generation-augmented retrieval for the TRECVid AVS task. Specifically, the understanding of textual query is enhanced by three generations, including Text2Text, Text2Image, and Image2Text, to address the out-of-vocabulary problem. Using different combinations of them and the rank list retrieved by the original query, we submitted four automatic runs. For manual runs, we use a large language model (LLM) (i.e., GPT4) to rephrase test queries based on the concept bank of the search engine, and we manually check again to ensure all the concepts used in the rephrased queries are in the bank. The result shows that the fusion of the original and generated queries outperforms the original query on TV24 query sets. The generated queries retrieve different rank lists from the original query.
@inproceedings{wu2024polysmartvireotrecvid, title = {PolySmart and VIREO @ TRECVid 2024 Ad-hoc Video Search}, author = {Wu, Jiaxin and Ngo, Chong-Wah and Wei, Xiao-Yong and Li, Qing}, booktitle = {NIST TRECVID Notebook 2024}, year = {2024}, } - ACM MM
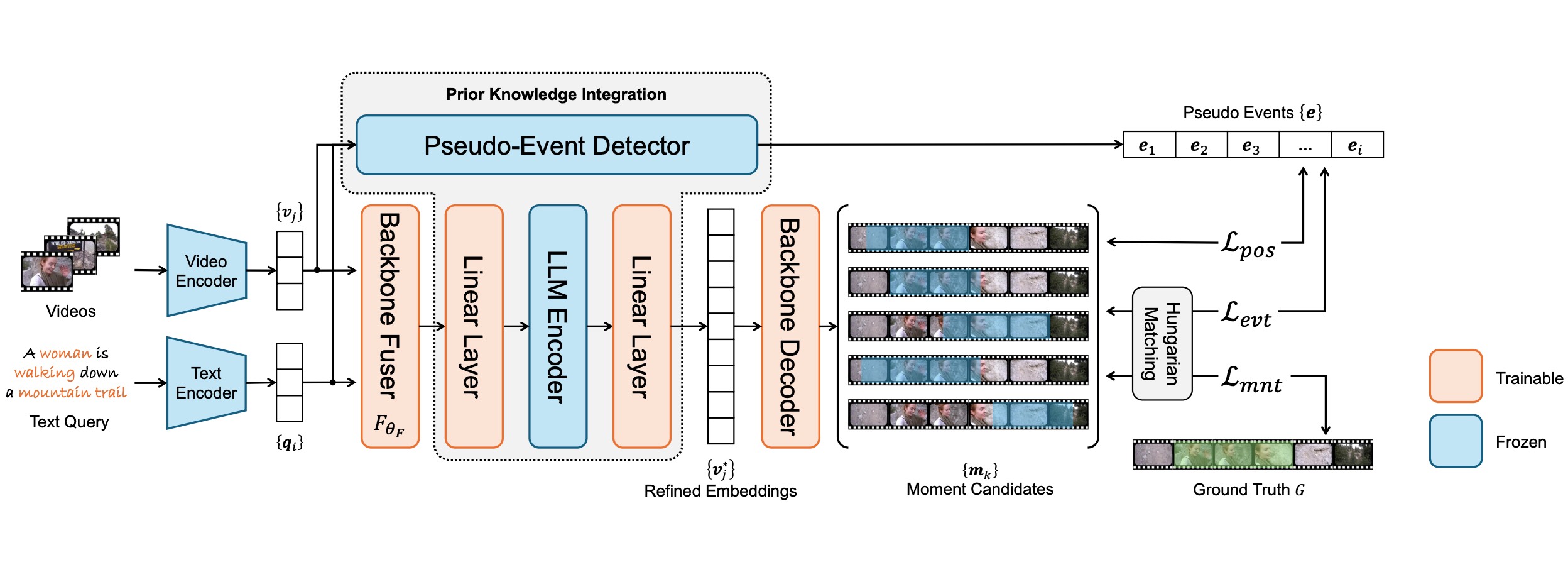 Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment RetrievalYiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiaoyong Wei, Chang Wen Chen, and Qing LiIn ACM Multimedia 2024 , Apr 2024
Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment RetrievalYiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiaoyong Wei, Chang Wen Chen, and Qing LiIn ACM Multimedia 2024 , Apr 2024In this paper, we investigate the feasibility of leveraging large language models (LLMs) for integrating general knowledge and incorporating pseudo-events as priors for temporal content distribution in video moment retrieval (VMR) models. The motivation behind this study arises from the limitations of using LLMs as decoders for generating discrete textual descriptions, which hinders their direct application to continuous outputs like salience scores and inter-frame embeddings that capture inter-frame relations. To overcome these limitations, we propose utilizing LLM encoders instead of decoders. Through a feasibility study, we demonstrate that LLM encoders effectively refine inter-concept relations in multimodal embeddings, even without being trained on textual embeddings. We also show that the refinement capability of LLM encoders can be transferred to other embeddings, such as BLIP and T5, as long as these embeddings exhibit similar inter-concept similarity patterns to CLIP embeddings. We present a general framework for integrating LLM encoders into existing VMR architectures, specifically within the fusion module. The LLM encoder’s ability to refine concept relation can help the model to achieve a balanced understanding of the foreground concepts (e.g., persons, faces) and background concepts (e.g., street, mountains) rather focusing only on the visually dominant foreground concepts. Additionally, we introduce the concept of pseudo-events, obtained through event detection techniques, to guide the prediction of moments within event boundaries instead of crossing them, which can effectively avoid the distractions from adjacent moments. The integration of semantic refinement using LLM encoders and pseudo-event regulation is designed as plug-in components that can be incorporated into existing VMR methods within the general framework. Through experimental validation, we demonstrate the effectiveness of our proposed methods by achieving state-of-the-art performance in VMR.
@inproceedings{jiang2024prior, title = {Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment Retrieval}, author = {Jiang, Yiyang and Zhang, Wengyu and Zhang, Xulu and Wei, Xiaoyong and Chen, Chang Wen and Li, Qing}, booktitle = {ACM Multimedia 2024}, year = {2024}, } - ACM MM
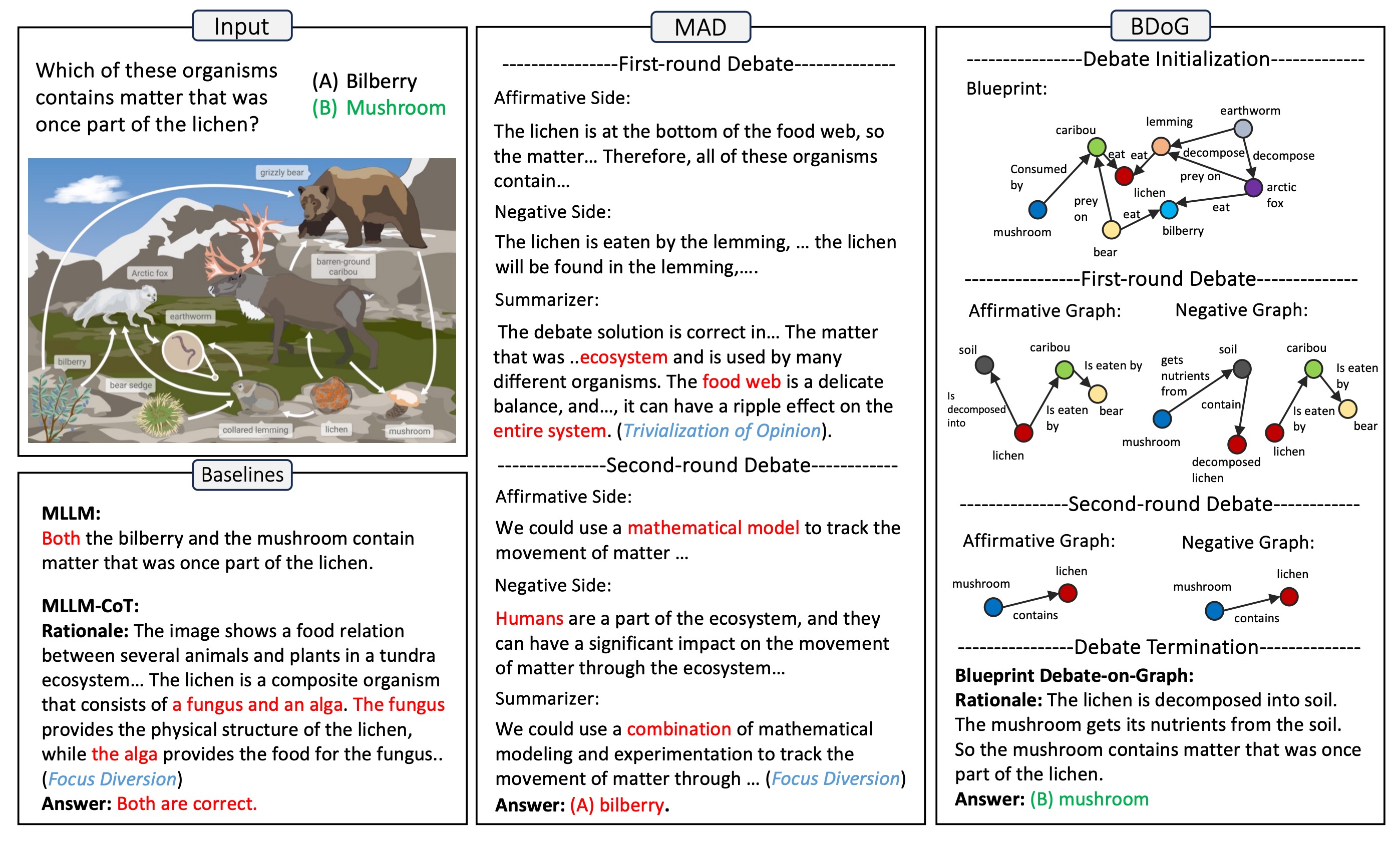 A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal ReasoningChangmeng Zheng, DaYong Liang, Wengyu Zhang, Xiaoyong Wei, Tat-Seng Chua, and Qing LiIn ACM Multimedia 2024 , Apr 2024
A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal ReasoningChangmeng Zheng, DaYong Liang, Wengyu Zhang, Xiaoyong Wei, Tat-Seng Chua, and Qing LiIn ACM Multimedia 2024 , Apr 2024This paper presents a pilot study aimed at introducing multi-agent debate into multimodal reasoning. The study addresses two key challenges: the trivialization of opinions resulting from excessive summarization and the diversion of focus caused by distractor concepts introduced from images. These challenges stem from the inductive (bottom-up) nature of existing debating schemes. To address the issue, we propose a deductive (top-down) debating approach called Blueprint Debate on Graphs (BDoG). In BDoG, debates are confined to a blueprint graph to prevent opinion trivialization through world-level summarization. Moreover, by storing evidence in branches within the graph, BDoG mitigates distractions caused by frequent but irrelevant concepts. Extensive experiments validate BDoG, achieving state-of-the-art results in Science QA and MMBench with significant improvements over previous methods.
@inproceedings{zheng2024a, title = {A Picture Is Worth a Graph: A Blueprint Debate Paradigm for Multimodal Reasoning}, author = {Zheng, Changmeng and Liang, DaYong and Zhang, Wengyu and Wei, Xiaoyong and Chua, Tat-Seng and Li, Qing}, booktitle = {ACM Multimedia 2024}, year = {2024}, } - ACM MM
 Generative Active Learning for Image Synthesis PersonalizationXulu Zhang, Wengyu Zhang, Xiaoyong Wei, Jinlin Wu, Zhaoxiang Zhang, Zhen Lei, and Qing LiIn ACM Multimedia 2024 , Apr 2024
Generative Active Learning for Image Synthesis PersonalizationXulu Zhang, Wengyu Zhang, Xiaoyong Wei, Jinlin Wu, Zhaoxiang Zhang, Zhen Lei, and Qing LiIn ACM Multimedia 2024 , Apr 2024This paper presents a pilot study that explores the application of active learning, traditionally studied in the context of discriminative models, to generative models. We specifically focus on image synthesis personalization tasks. The primary challenge in conducting active learning on generative models lies in the open-ended nature of querying, which differs from the closed form of querying in discriminative models that typically target a single concept. We introduce the concept of anchor directions to transform the querying process into a semi-open problem. We propose a direction-based uncertainty sampling strategy to enable generative active learning and tackle the exploitation-exploration dilemma. Extensive experiments are conducted to validate the effectiveness of our approach, demonstrating that an open-source model can achieve superior performance compared to closed-source models developed by large companies, such as Google’s StyleDrop. The source code is available at https://github.com/zhangxulu1996/GAL4Personalization
@inproceedings{zhang2024generative, title = {Generative Active Learning for Image Synthesis Personalization}, author = {Zhang, Xulu and Zhang, Wengyu and Wei, Xiaoyong and Wu, Jinlin and Zhang, Zhaoxiang and Lei, Zhen and Li, Qing}, booktitle = {ACM Multimedia 2024}, year = {2024}, } - AAAI
 Compositional inversion for stable diffusion modelsXulu Zhang, Xiao-Yong Wei, Jinlin Wu, Tianyi Zhang, Zhaoxiang Zhang, Zhen Lei, and Qing LiIn Proceedings of the AAAI Conference on Artificial Intelligence , Apr 2024
Compositional inversion for stable diffusion modelsXulu Zhang, Xiao-Yong Wei, Jinlin Wu, Tianyi Zhang, Zhaoxiang Zhang, Zhen Lei, and Qing LiIn Proceedings of the AAAI Conference on Artificial Intelligence , Apr 2024Inversion methods, such as Textual Inversion, generate personalized images by incorporating concepts of interest provided by user images. However, existing methods often suffer from overfitting issues, where the dominant presence of inverted concepts leads to the absence of other desired concepts. It stems from the fact that during inversion, the irrelevant semantics in the user images are also encoded, forcing the inverted concepts to occupy locations far from the core distribution in the embedding space. To address this issue, we propose a method that guides the inversion process towards the core distribution for compositional embeddings. Additionally, we introduce a spatial regularization approach to balance the attention on the concepts being composed. Our method is designed as a post-training approach and can be seamlessly integrated with other inversion methods. Experimental results demonstrate the effectiveness of our proposed approach in mitigating the overfitting problem and generating more diverse and balanced compositions of concepts in the synthesized images. The source code is available at https://github.com/zhangxulu1996/Compositional-Inversion.
@inproceedings{zhang2024compositional, title = {Compositional inversion for stable diffusion models}, author = {Zhang, Xulu and Wei, Xiao-Yong and Wu, Jinlin and Zhang, Tianyi and Zhang, Zhaoxiang and Lei, Zhen and Li, Qing}, paper = {https://ojs.aaai.org/index.php/AAAI/article/view/28565}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence}, volume = {38}, number = {7}, pages = {7350--7358}, year = {2024}, publisher = {AAAI}, }






